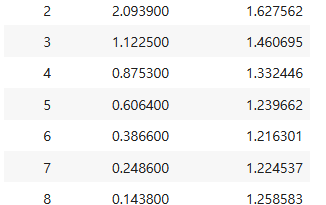
파이썬 insightface로 동영상의 얼굴 바꾸기 (파이썬 딥페이크 합성)
저번 글에서는 이미지의 얼굴을 다른 얼굴로 합성해봤습니다. 이번에는 얼굴이 하나 나오는 단순한 영상의 얼굴을 다른 얼굴로 바꿔보겠습니다
목차
라이브러리 설치, 모델 다운로드
이미지의 얼굴을 바꿀 때와 필요한 라이브러리는 비슷합니다. 동영상을 불러오는데 opencv를 이용하고 동영상 얼굴 합성 진행도를 확인하기 위해 tqdm 라이브러리를 이용하겠습니다. opencv는 동영상의 소리는 가져오지 않기 때문에 동영상의 소리는 ffmpeg나 다른 툴을 이용해서 넣어줘야합니다.
라이브러리 설치
pip install insightface opencv-python tqdm사용하는 환경에 맞게 onnxruntime 라이브러리 설치
pip install onnxruntimepip install onnxruntime-gpupip install onnxruntime-gpu --extra-index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/onnxruntime-cuda-12/pypi/simple/pip install ort-nightly-gpu --index-url=https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/ort-cuda-12-nightly/pypi/simple/얼굴 합성 모델 다운로드
얼굴을 바꾸기 위한 inswapper 모델을 다운로드 받고 작업할 폴더를 만들어 그 안에 넣어줍니다.
다운로드 링크 : https://huggingface.co/ezioruan/inswapper_128.onnx/resolve/main/inswapper_128.onnx?download=true
리눅스나 코랩의 경우 wget을 이용해 다운로드 받을 수 있습니다. 작업폴더의 경로에서 아래 명령을 실행해줍니다.
wget https://huggingface.co/ezioruan/inswapper_128.onnx/resolve/main/inswapper_128.onnx?download=true -O inswapper_128.onnx다른 이미지의 얼굴을 참조해 동영상 얼굴 합성
편의상 작업폴더에 얼굴합성에 참조할 이미지와 얼굴을 바꿀 영상을 넣어줍니다. 넣지 않아도 코드 상에서 경로를 알맞게 설정해주면 됩니다(inswapper 모델도 마찬가지).
import cv2
import insightface
from insightface.app import FaceAnalysis
from tqdm import tqdm
app = FaceAnalysis(allowed_modules=['detection','recognition'], providers=['CPUExecutionProvider', 'CUDAExecutionProvider'])
app.prepare(ctx_id=0, det_thresh=0.5, det_size=(640, 640))
swapper = insightface.model_zoo.get_model('inswapper_128.onnx',providers=['CPUExecutionProvider', 'CUDAExecutionProvider'])라이브리와 얼굴탐지, 얼굴인식, 얼굴합성 모델을 불러옵니다. 자세한 내용은 저번 글에 나와있습니다.
img1 = cv2.imread('source.jpg')
faces1 = app.get(img1)
input_video = "input.mp4"
cap = cv2.VideoCapture(input_video)
size = (int(cap.get(3)),int(cap.get(4)))
fps= int(cap.get(5))
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
output_video = "output.mp4"
out = cv2.VideoWriter(output_video,cv2.VideoWriter_fourcc(*'mp4v'),fps,size)
for _ in tqdm(range(frame_count)):
ret, frame = cap.read()
if not ret:
break
faces2 = app.get(frame)
frame = swapper.get(frame, faces2[0], faces1[0], paste_back=True)
out.write(frame)
cap.release()
out.release()코드의 내용을 요약하면 다음과 같습니다.
- opencv를 이용해 참조할 얼굴의 이미지를 불러오고 app.get을 통해 얼굴탐지와 얼굴인식을 수행해 Face객체들의 리스트를 얻습니다.
- opencv를 이용해 영상을 불러오고 영상의 크기, 초 당 프레임, 총 프레임 수를 얻어옵니다.
- 2번에서 얻어온 크기, fps를 이용해 합성결과가 담길 파일을 설정합니다.
- 총 프레임수만큼 반복문을 돌려 영상의 프레임을 하나씩 읽어오고 얼굴탐지, 인식을 한 후 합성을 한 결과를 출력파일에 씁니다.
- 반복문이 끝나면 videowriter와 videocapture를 해제합니다.
영상으로 테일러 스위프트 인터뷰의 일부를 잘라서 사용했고 참조되는 얼굴로 이시하라 사토미의 얼굴 이미지를 이용했습니다.

아래가 그 결과입니다.
만약 영상에 여러 얼굴이 나온다면 얼굴인식을 이용해 유사도를 비교하고 트래킹을 이용해 얼굴을 추적해서 특정 얼굴만 합성할 수도 있습니다. 그리고 영상의 품질을 개선하려면 이 글의 방법을 이용할 수 있습니다. 또한 이미지의 얼굴 합성 글에서 이미지 없이 얼굴 임베딩 벡터를 생성해 합성을 했었는데 같은 방법으로 영상에도 적용할 수 있습니다