GroundingDino 를 이용해 객체탐지하고 세그멘테이션에 이용하기
GroundingDino 는 Zero-Shot Object Detection를 수행하는 모델로 정해진 레이블만 탐지하는 것이 아니라 입력으로 주어진 텍스트를 기반으로 객체탐지를 수행합니다. GroundingDino에 탐지대상에
더 읽어보기다양한 정보 – 스타크래프트, 그림AI, 동물, 파이썬 등
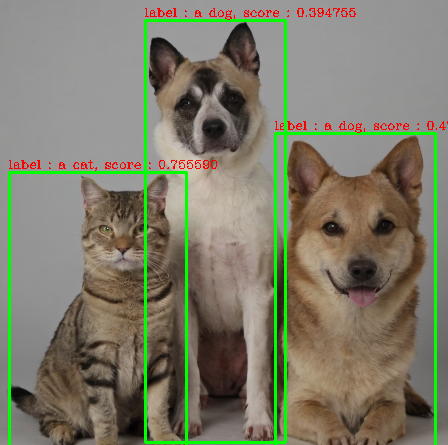
GroundingDino 는 Zero-Shot Object Detection를 수행하는 모델로 정해진 레이블만 탐지하는 것이 아니라 입력으로 주어진 텍스트를 기반으로 객체탐지를 수행합니다. GroundingDino에 탐지대상에
더 읽어보기
저번 글에서 객체에 대한 점을 입력으로 전달해 세그멘테이션을 하고 배경제거를 해봤습니다. 이번 글에서는 추가로 객체를 포함하는 박스와 점에 대한 라벨을
더 읽어보기
세그멘테이션 (segmentation)은 이미지나 영상의 특정 객체에 대한 픽셀들의 좌표를 구해 다른 물체나 배경과 구별하는 기술입니다. Meta에서 만든 SAM은 세그멘테이션을 위한
더 읽어보기