
LangChain, LangGraph를 이용해서 RAG (검색증강생성) 하기
목차
LangChain, LangGraph
LangChain은 언어모델을 쉽게 다룰 수 있게 도와주는 파이썬 프레임워크입니다.
API를 통해 사용하는 OpenAI, Google의 언어모델도 사용할 수 있고 gemma, qwen, llama 등의 로컬 언어모델도 사용할 수 있는데 여러 가지 언어모델에 대해 거의 같은 코드로 사용할 수 있습니다.
LangChain 또는 LangGraph를 이용해서 프롬프트 부분, 텍스트 생성 부분, 후처리 부분, 검색증강생성 부분 등을 연결해 전체 프로세스를 만드는데 LangGraph의 경우 복잡한 기능을 만들 때 LangChain 보다 좋고 State를 통해 값들이 전달되기 때문에 편리한 점이 있습니다.
검색증강생성 RAG(Retrieval-Augmented Generation)
RAG는 Retrieval-Augmented Generation의 약자로 한국어로는 검색증강생성이라고 합니다.
언어모델은 학습되지 않은 데이터에 대한 정보가 없기 때문에 최근의 정보나 마이너한 정보에 대해서는 텍스트를 잘 생성하지 못합니다.
RAG는 사용자가 입력한 프롬프트와 관련이 있는 정보를 벡터DB에서 찾아 사용자의 프롬프트에 추가해 언어모델에게 전달함으로써 추가적인 정보를 기반으로 텍스트를 생성하도록 합니다.
프롬프트에 내용을 추가하는 것이기 때문에 프롬프트 엔지니어링이 중요합니다. 너무 추가적인 정보에만 의존해 내용을 생성하면 답변이 단조로울 수 있습니다.
사용자가 입력한 프롬프트와 유사한 정보를 찾기 위해 프롬프트와 문서의 벡터임베딩끼리 유사도를 계산해 유사도가 높은 문서를 가져옵니다.
실습
코랩 T4 GPU 환경에서 LangChain, LangGraph, RAG를 간단하게 다뤄보겠습니다. 언어모델은 구글의 언어모델 gemma3 12B, 임베딩 모델은 알리바바 클라우드의 Qwen 0.6B를 사용합니다.
라이브러리 설치
GGUF 포맷의 모델을 사용하려면 llama cpp를 사용해야 하는데 코랩에서 pip install llama-cpp-python 으로 설치할 경우 GPU를 사용하지 않고 예전 버전을 설치하면 GPU를 사용하지만 gemma3이 지원되지 않습니다.
그래서 https://github.com/oobabooga/llama-cpp-python-cuBLAS-wheels/releases/tag/textgen-webui 에 올라온 코랩 환경에 맞는 0.3.8 버전을 설치합니다. 참고로 이 저장소의 소유자는 우바부가라고도 불리는 LLM UI 인 textgen-webui 소유자와 같습니다.
그리고 langgraph, langchain, faiss 등의 라이브러리도 설치해줍니다. faiss는 메타에서 만든 라이브러리로 벡터DB에서 검색하는 것과 관련이 있습니다. faiss-gpu로 설치하면 gpu를 사용하지만 여기서는 cpu로 설치하겠습니다.
!pip install https://github.com/oobabooga/llama-cpp-python-cuBLAS-wheels/releases/download/textgen-webui/llama_cpp_python_cuda-0.3.8+cu124-cp311-cp311-linux_x86_64.whl
!pip install langgraph langchain-community langchain-huggingface sentence-transformers faiss-cpu모델 다운로드
gemma3 12B의 4비트 양자화버전을 사용하겠습니다. 모델 가중치의 정밀도가 줄었기 때문에 성능은 떨어지지만 메모리가 절약되고 속도가 향상됩니다.
!wget https://huggingface.co/bartowski/google_gemma-3-12b-it-GGUF/resolve/main/google_gemma-3-12b-it-Q4_K_M.gguf모델이 다운로드 됬으면 언어모델 로드 부분의 내용을 확인해 코드를 수정하고 돌아오시는게 좋습니다.
벡터 DB 구성
실제 데이터베이스를 구성하지는 않고 메모리에만 올려서 사용합니다.
텍스트를 임베딩 해 벡터로 만들려면 임베딩모델이 필요합니다. api를 이용해 OpenAI나 구글의 임베딩 모델을 이용할 수 있는데 언어모델을 이용하는 것과 마찬가지로 사용량에 따라 비용이 들기 때문에 로컬 임베딩 모델을 사용하겠습니다.
알리바바 클라우드의 Qwen3 Embedding 0.6B를 허깅페이스에서 다운로드 받고 불러오겠습니다.
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="Qwen/Qwen3-Embedding-0.6B")faiss로 인덱스를 만드는데 유사도 계산 방식을 정하고 벡터의 차원을 넘겨줍니다. 아무 텍스트나 임베딩하고 길이를 구해 텍스트가 몇 개의 숫자로 임베딩 되는지 알 수 있습니다. 또한 L2거리로 유사도를 계산하고 거리가 가까우면 유사도가 높습니다.
이후 벡터 저장소를 만드는데 embedding, index 등을 전달합니다.
import faiss
from langchain_community.vectorstores import FAISS
from langchain_community.docstore.in_memory import InMemoryDocstore
index = faiss.IndexFlatL2(len(embeddings.embed_query("hello world")))
vector_store = FAISS(
embedding_function=embeddings,
index=index,
docstore=InMemoryDocstore(),
index_to_docstore_id={},
)이제 벡터 저장소에 문서를 추가합니다. 여기서는 짧은 문장을 직접 작성했지만 csv 파일로부터 문서를 만들 수도 있고 웹검색 결과로도 만들 수 있습니다.
page_content가 임베딩 되고 메타데이터는 필요에 따라 출처, 카테고리 등의 내용을 넣어 줍니다. 저장소에서 검색할 때 메타데이터로 필터링을 할 수도 있습니다. uuid4로 식별자를 만들었습니다.
from langchain_core.documents import Document
from uuid import uuid4
document_1 = Document(
page_content="삼성전자의 주가는 6만원 정도다.",
metadata={"category": "stock"},
)
document_2 = Document(
page_content="미국은 이란을 폭격했다.",
metadata={"category": "news"},
)
document_3 = Document(
page_content="gemma3 모델의 한국어 성능이 좋다고 들었다.",
metadata={"category": "tech"},
)
document_4 = Document(
page_content="한국의 산개구리 종류는 계곡산개구리, 큰산개구리, 한국산개구리가 있다.",
metadata={"category": "biology"},
)
document_5 = Document(
page_content="한국의 지금 대통령은 이재명이다.",
metadata={"category": "society"},
)
document_6 = Document(
page_content="구글의 Veo3는 음성이 있는 영상을 생성한다.",
metadata={"category": "tech"},
)
document_7 = Document(
page_content="곧 갤럭시Z플립7이 공개된다.",
metadata={"category": "tech"},
)
document_8 = Document(
page_content="다음 ios 버전은 26이다.",
metadata={"category": "tech"},
)
documents = [
document_1,
document_2,
document_3,
document_4,
document_5,
document_6,
document_7,
document_8,
]
uuids = [str(uuid4()) for _ in range(len(documents))]
vector_store.add_documents(documents=documents, ids=uuids)index에는 벡터가 저장되어있고 vector_store.index_to_docstore_id는 index의 벡터 순서와 문서의 식별자를 연결해줍니다.
index.reconstruct_n(0, 8)
'''출력 예시
array([[-0.01468298, 0.00363755, 0.00150874, ..., 0.05389853,
0.0357578 , -0.01964616],
[-0.00671843, -0.0116294 , 0.00388943, ..., -0.02243297,
0.03723721, 0.02116461],
[-0.04103446, -0.04099684, -0.00084605, ..., 0.03394905,
-0.05007358, 0.02135903],
...,
[-0.01022102, -0.04480148, -0.00692248, ..., 0.0641152 ,
-0.00188996, 0.02132382],
[ 0.03665596, -0.01942061, 0.00107364, ..., -0.0105516 ,
0.01997301, -0.00870296],
[-0.03863299, -0.02887104, -0.00422517, ..., 0.02170919,
0.04838681, -0.00880432]], dtype=float32)'''vector_store.index_to_docstore_id
'''출력 예시
{0: '685d337d-db0f-444e-b748-6c508532b6a7',
1: '96fc97b4-cd42-47b0-8ed4-de8e6e068b33',
2: 'a68d500e-d228-4783-9bed-474f08c3be96',
3: 'fd660f93-631e-4cf7-838e-cd51809eead0',
4: 'ff51ae71-d7ee-4141-b135-8e9bc193e5f7',
5: '81e0f5bd-ca00-4f62-9f81-7533b52c72fb',
6: '8cfadee0-41b9-40c9-ad48-73f5ea83e10c',
7: '7d369c91-2686-4349-a726-cbfc33618ceb'}'''저장된 내용도 확인할 수 있습니다.
vector_store.get_by_ids(uuids)
'''출력 예시
[Document(id='685d337d-db0f-444e-b748-6c508532b6a7', metadata={'category': 'stock'}, page_content='삼성전자의 주가는 6만원 정도다.'),
Document(id='96fc97b4-cd42-47b0-8ed4-de8e6e068b33', metadata={'category': 'news'}, page_content='미국은 이란을 폭격했다.'),
Document(id='a68d500e-d228-4783-9bed-474f08c3be96', metadata={'category': 'tech'}, page_content='gemma3 모델의 한국어 성능이 좋다고 들었다.'),
Document(id='fd660f93-631e-4cf7-838e-cd51809eead0', metadata={'category': 'biology'}, page_content='한국의 산개구리 종류는 계곡산개구리, 큰산개구리, 한국산개구리가 있다.'),
Document(id='ff51ae71-d7ee-4141-b135-8e9bc193e5f7', metadata={'category': 'society'}, page_content='한국의 지금 대통령은 이재명이다.'),
Document(id='81e0f5bd-ca00-4f62-9f81-7533b52c72fb', metadata={'category': 'tech'}, page_content='구글의 Veo3는 음성이 있는 영상을 생성한다.'),
Document(id='8cfadee0-41b9-40c9-ad48-73f5ea83e10c', metadata={'category': 'tech'}, page_content='곧 갤럭시Z플립7이 공개된다.'),
Document(id='7d369c91-2686-4349-a726-cbfc33618ceb', metadata={'category': 'tech'}, page_content='다음 ios 버전은 26이다.')]'''이렇게 만들어진 벡터 DB에서 입력한 쿼리와 유사한 문서를 검색해보겠습니다. 쿼리와 얻어올 문서의 갯수를 전달합니다.
vector_store.similarity_search(query="Can you explain about species of frogs in america?",k=2)
'''출력 예시
[Document(id='fd660f93-631e-4cf7-838e-cd51809eead0', metadata={'category': 'biology'}, page_content='한국의 산개구리 종류는 계곡산개구리, 큰산개구리, 한국산개구리가 있다.'),
Document(id='96fc97b4-cd42-47b0-8ed4-de8e6e068b33', metadata={'category': 'news'}, page_content='미국은 이란을 폭격했다.')]'''similarity_search_with_score를 사용하면 거리를 포함한 결과를 줍니다.
언어모델 로드
ChatLlamaCpp로 모델을 불러옵니다. 모델마다 정해진 프롬프트 템플릿이 있는데 내부적으로 이를 처리해줍니다. 파라미터에 대한 정보는 공식 문서에 나와 있습니다.
from langchain_community.chat_models import ChatLlamaCpp
GGUF_FILE_PATH = "google_gemma-3-12b-it-Q4_K_M.gguf"
chat_llm = ChatLlamaCpp(
model_path=GGUF_FILE_PATH,
n_gpu_layers=-1,
n_batch=512,
n_ctx=8192,
max_tokens = 512,
f16_kv=True,
verbose=False,
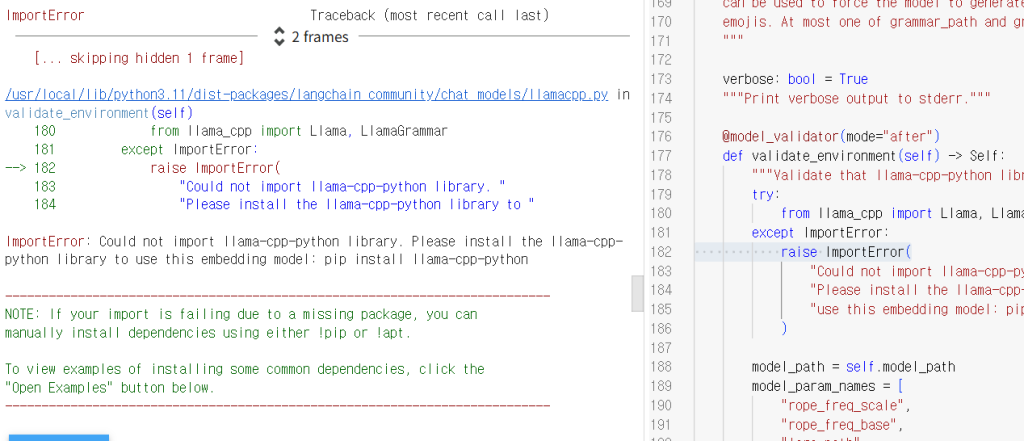
)llama cpp를 따로 설치했기 때문에 위의 코드를 실행하면 에러가 납니다. llama_cpp가 아니라 llama_cpp_cuda에서 import를 하게 코드를 수정해줍니다.
에러 출력에서 파란색 경로를 클릭하면 오른쪽에 코드가 나오는데 from llama_cpp를 from llama_cpp_cuda로 바꾸고 ctrl+s로 저장해줍니다. 그리고 런타임 – 세션 다시 시작을 해줍니다. 다운로드 받은 파일은 남아있지만 변수들은 다 날아갔습니다.
상태 정의
우선 검색증강생성 챗봇에 사용할 상태를 정의합니다. 이 경우 대화 기록과 참조할 문서가 필요합니다.
from typing import TypedDict, Annotated, List
from langchain_core.messages import AnyMessage
class RAGChatState(TypedDict):
messages: Annotated[list[AnyMessage], lambda x, y: x + y]
context: List[Document]messages는 대화 기록을 가지고 있고 context는 유사도 검색을 통해 가져온 문서들을 담고 있습니다.
체인 구성
대화 기록을 입력 받아 생성 결과를 텍스트로 출력하는 체인을 만듭니다.
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder(variable_name="messages_list")
])
chain = prompt | chat_llm | StrOutputParser()| 로 연결이 되어 있고 1. 템플릿 적용 2. 언어모델로 생성 3. 내용만 파싱 의 과정을 거칩니다.
이렇게 만든 체인을 부분 별로 테스트 해보겠습니다.
우선 prompt에 메시지목록을 전달해 어떤 결과가 나오는지 보겠습니다.
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage, AIMessageChunk
prompt.invoke({'messages_list' : [HumanMessage(content='I am Tom'), AIMessage(content='Hi'), HumanMessage(content='Who am I?')]})
'''출력 예시
ChatPromptValue(messages=[HumanMessage(content='I am Tom', additional_kwargs={}, response_metadata={}), AIMessage(content='Hi', additional_kwargs={}, response_metadata={}), HumanMessage(content='Who am I?', additional_kwargs={}, response_metadata={})])'''invoke에 딕셔너리 형태로 넣어줍니다. 키는 variable_name과 같게 쓰고 value는 메시지들의 리스트가 됩니다.
HumanMessage는 사람의 메시지, AIMessage는 언어모델의 메시지입니다. SystemMessage는 모델에 역할 부여 등을 하는데 gemma에서는 쓰이지 않습니다.
이렇게 나온 ChatPromptValue가 chat_llm에 전달됩니다.
다음은 prompt | chat_llm 에 invoke를 해보겠습니다.
chain_part = prompt | chat_llm
chain_part.invoke({'messages_list' : [HumanMessage(content='I am Tom'), AIMessage(content='Hi'), HumanMessage(content='Who am I?')]})
'''출력 예시
AIMessage(content='You told me you are Tom! 😊', additional_kwargs={}, response_metadata={'finish_reason': 'stop'}, id='run--800dc87e-e2d0-41c8-ac62-6e1eb9dbfa12-0')'''AIMessage로 결과가 나옵니다. 전체 체인의 마지막 부분인 StrOutputParser() 를 거치면 ‘You told me you are Tom! 😊’ 만 결과로 나오게 됩니다.
문서 검색 노드 함수
사용자의 마지막 입력과 유사한 문서를 검색해서 상태의 context에 넣습니다.
def retrieve_node(state: RAGChatState):
print("--- retrieve_node : RETRIEVING DOCUMENTS ---")
user_question = state['messages'][-1].content
retrieved_docs = vector_store.similarity_search(user_question, k=2)
return {"context": retrieved_docs}state[‘messages’][-1].content 로 사용자의 마지막 입력 내용을 가져와서 벡터 저장소에서 문서를 찾습니다. k=2로 가장 유사한 2개를 찾게 했습니다.
검색증강생성 노드 함수
사용자의 프롬프트에 검색된 문서의 내용을 추가하고 이전 채팅 기록과 함께 체인에 넘겨 텍스트를 생성합니다. 과정을 파악할 수 있게 print문을 넣어놨습니다.
def generate_node(state: RAGChatState):
print("--- generate_node : GENERATING ANSWER ---")
context_str = "\n\n".join(doc.page_content for doc in state['context'])
system_instruction = ""
last_user_message = state['messages'][-1]
previous_history = state['messages'][:-1]
full_prompt_for_this_turn = f"""{system_instruction}
### Retrieved Context:
{context_str}
### User's Question:
{last_user_message.content}
"""
current_human_message = HumanMessage(content=full_prompt_for_this_turn)
messages_to_send = previous_history + [current_human_message]
print("\n--- [DEBUG] Messages history + Final messages being sent to LLM ---")
for msg in messages_to_send:
msg.pretty_print()
print()
print("\n--- [DEBUG END] Messages history + Final messages being sent to LLM ---\n")
answer = chain.invoke({"messages_list": messages_to_send})
#answer = chain_part.invoke({"messages_list": messages_to_send})
return {"messages": [AIMessage(content=answer)]}
#return {"messages": [answer]}full_prompt_for_this_turn 가 사용자의 최종적인 프롬프트가 됩니다. 내부에는 system_instruction, context_str, last_user_message.content 세가지 변수가 있습니다.
system_instruction은 시스템 프롬프트의 내용으로 gemma는 시스템프롬프트가 없기 때문에 비슷하게 사용하려면 user 프롬프트에 내용을 넣어줍니다. 여기서는 아무 내용도 넣지 않았습니다.
context_str는 검색된 문서의 내용을 줄바꿈 두번으로 결합한 문자열입니다.
last_user_message.content 는 사용자가 입력한 내용입니다.
최종 프롬프트를 HumanMessage로 감싸고 이전 채팅 기록과 합쳐서 체인에 전달해 텍스트를 생성합니다.
주석은 StrOutputParser()가 적용되지 않은 chain_part를 이용하는 것으로 결과가 AIMessage기 때문에 다시 감쌀 필요가 없습니다.
그래프 구성
두 함수를 연결 해 그래프를 만듭니다. 채팅기록은 메모리에 저장합니다.
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph, END, START
memory = MemorySaver()
graph_builder = StateGraph(RAGChatState)
graph_builder.add_node("retrieve", retrieve_node)
graph_builder.add_node("generate", generate_node)
graph_builder.set_entry_point("retrieve")
graph_builder.add_edge("retrieve", "generate")
graph_builder.add_edge("generate", END)
chat_graph = graph_builder.compile(checkpointer=memory)그래프 사용
config의 thread_id별로 채팅이 기록됩니다. generate 노드가 완료된 경우 메시지를 출력합니다.
conversation_id = str(uuid4())
config = {"configurable": {"thread_id": conversation_id}}
while True:
user_input = input("User: ")
if user_input.lower() in ["exit", "quit"]:
break
inputs = {"messages": [HumanMessage(content=user_input)]}
response_message = None
for event in chat_graph.stream(inputs, config=config,):
if "generate" in event:
response_message = event["generate"]["messages"][-1]
if response_message:
print("AI:", response_message.content)
'''event 예시
{'retrieve': {'context': [Document(id='313772a8-fe6a-4bff-8881-1917dc8bf314', metadata={'category': 'tech'}, page_content='구글의 Veo3는 음성이 있는 영상을 생성한다.'), Document(id='5c904064-53e0-4f33-b171-4940f48d8fe2', metadata={'category': 'tech'}, page_content='다음 ios 버전은 26이다.')]}}
{'generate': {'messages': [AIMessage(content='Hi there! 😊 \n\n\n\nIs there anything I can help you with today?', additional_kwargs={}, response_metadata={'finish_reason': 'stop'}, id='run--7ccd4fad-7bf4-4478-a7e5-97d5889bfb84-0')]}}'''이 경우 전체 텍스트가 한번에 출력됩니다.

생성된 내용을 바로바로 출력하려면 코드를 바꿔야합니다.
conversation_id = str(uuid4())
config = {"configurable": {"thread_id": conversation_id}}
while True:
user_input = input("User: ")
print()
if user_input.lower() in ["exit", "quit"]:
break
inputs = {"messages": [HumanMessage(content=user_input)]}
response_message = None
c=0
for message_chunk, metadata in chat_graph.stream(inputs, config=config, stream_mode="messages"):
if type(message_chunk) == AIMessageChunk:
if c==0:
print("AI: ", end='', flush=True)
c=1
print(message_chunk.content, end="", flush=True)
print('\n\n')
'''
message_chunk 타입, 내용 출력 예시
<class 'langchain_core.messages.ai.AIMessageChunk'> : content='' additional_kwargs={} response_metadata={} id='run--05bb6fd3-9034-4cdb-a35b-472924eae15a'
<class 'langchain_core.messages.ai.AIMessageChunk'> : content='Hi' additional_kwargs={} response_metadata={} id='run--05bb6fd3-9034-4cdb-a35b-472924eae15a'
<class 'langchain_core.messages.ai.AIMessageChunk'> : content=' there' additional_kwargs={} response_metadata={} id='run--05bb6fd3-9034-4cdb-a35b-472924eae15a'
<class 'langchain_core.messages.ai.AIMessageChunk'> : content='!' additional_kwargs={} response_metadata={} id='run--05bb6fd3-9034-4cdb-a35b-472924eae15a'
<class 'langchain_core.messages.ai.AIMessageChunk'> : content=' How' additional_kwargs={} response_metadata={} id='run--05bb6fd3-9034-4cdb-a35b-472924eae15a'
<class 'langchain_core.messages.ai.AIMessageChunk'> : content=' can' additional_kwargs={} response_metadata={} id='run--05bb6fd3-9034-4cdb-a35b-472924eae15a'
<class 'langchain_core.messages.ai.AIMessageChunk'> : content=' I' additional_kwargs={} response_metadata={} id='run--05bb6fd3-9034-4cdb-a35b-472924eae15a'
<class 'langchain_core.messages.ai.AIMessageChunk'> : content=' help' additional_kwargs={} response_metadata={} id='run--05bb6fd3-9034-4cdb-a35b-472924eae15a'
<class 'langchain_core.messages.ai.AIMessageChunk'> : content=' you' additional_kwargs={} response_metadata={} id='run--05bb6fd3-9034-4cdb-a35b-472924eae15a'
<class 'langchain_core.messages.ai.AIMessageChunk'> : content=' today' additional_kwargs={} response_metadata={} id='run--05bb6fd3-9034-4cdb-a35b-472924eae15a'
<class 'langchain_core.messages.ai.AIMessageChunk'> : content='?' additional_kwargs={} response_metadata={} id='run--05bb6fd3-9034-4cdb-a35b-472924eae15a'
<class 'langchain_core.messages.ai.AIMessageChunk'> : content='' additional_kwargs={} response_metadata={'finish_reason': 'stop'} id='run--05bb6fd3-9034-4cdb-a35b-472924eae15a'
<class 'langchain_core.messages.ai.AIMessage'> : content='Hi there! How can I help you today?' additional_kwargs={} response_metadata={} id='193719a2-337d-4e1c-9405-c2c1c7aa0298'
'''stream_mode를 messages로 두고 AIMessageChunk타입을 받은 경우에만 출력합니다. stream_mode가 바뀌어 노드함수의 결과가 아닌 메시지청크와 메시지를 받아옵니다. 메시지청크를 이용해 스트리밍 출력을 할 수 있습니다.

이 그래프는 항상 검색증강생성을 하도록 되어있지만 그래프에 분기를 추가해 검색증강생성이 필요하다고 판단될 경우만 검색증강생성을 하게 하는 등의 기능을 추가할 수 있습니다.
fastapi 등으로 백엔드를 구성하고 프론트엔드와 연결해 사용할 수 있습니다.


