GroundingDino 를 이용해 객체탐지하고 세그멘테이션에 이용하기
GroundingDino 는 Zero-Shot Object Detection를 수행하는 모델로 정해진 레이블만 탐지하는 것이 아니라 입력으로 주어진 텍스트를 기반으로 객체탐지를 수행합니다. GroundingDino에 탐지대상에 대한 텍스트를 전달하면 탐지대상에 대한 박스를 예측해서 결과로 줍니다. GroundinigDino의 결과로 나온 박스들을 SAM(Segment Anything Model)에 전달하면 프롬프트를 통한 세그멘테이션을 수행할 수 있습니다. 결과적으로 텍스트를 전달해 세그멘테이션을 하는 것과 같습니다.
이 글에서는 GroundingDino를 이용해 객체탐지를 하고 추가로 세그멘테이션까지 해보겠습니다.
목차
라이브러리 설치
transformers, torch, matplotlib, numpy, PIL, opencv를 설치해줍니다. 모델 사용과 이미지를 다루기 위한 라이브러리들입니다.
pip install transformers matplotlib numpy pillow opencv-pythontorch는 https://pytorch.kr/get-started/locally/ 이 링크에서 환경에 맞는 명령어로 설치해줍니다.
코랩은 위의 라이브러리들이 설치되어 있습니다.
GroundingDino 객체탐지 하기
필요한 라이브러리를 불러오고 cuda 사용 여부에 따라 device를 설정합니다.
from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
import torch
from PIL import Image
import cv2
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")GroundingDino는 base모델과 tiny모델이 있는데 base 모델을 이용해서 객체탐지를 하겠습니다. 허깅페이스에서 모델을 불러옵니다.
model_gd = AutoModelForZeroShotObjectDetection.from_pretrained("IDEA-Research/grounding-dino-base").to(device)
processor_gd = AutoProcessor.from_pretrained("IDEA-Research/grounding-dino-base")객체탐지 할 이미지를 PIL.Image와 opencv를 이용해 불러오겠습니다. AI로 만든 이미지를 이용하겠습니다. 투명도가 있는 RGBA 이미지의 경우 RGB 타입으로 바꿔줍니다. opencv로 불러온 이미지는 시각화에 쓰이게 됩니다.
img = Image.open('image.png')
if img.mode == 'RGBA':
img = img.convert('RGB')
img_cv2 = cv2.imread('image.png')
고양이와 강아지를 탐지하기 위한 텍스트를 만들겠습니다. 텍스트의 작은 변화가 결과에 영향을 주는데 ‘cat. dog.’로 입력한 경우는 아래의 프롬프트와 결과가 다르게 나옵니다.
prompt = 'a cat. a dog.'다음으로 모델에 이미지와 텍스트를 전달합니다.
inputs = processor_gd(images=img, text=prompt, return_tensors="pt",).to(device)
with torch.no_grad():
outputs = model_gd(**inputs)
results = processor_gd.post_process_grounded_object_detection(
outputs,
inputs.input_ids,
box_threshold=0.3,
text_threshold=0.3,
target_sizes = [img.size[::-1]]
)여기서 box_threshold와 text_threshold를 크게 하면 점수가 높은 대상만 탐지를 하기 때문에 탐지가 잘 안되면 값을 내리면 됩니다. 너무 낮게 하면 원하지 않는 대상이 탐지 될 수 있습니다.
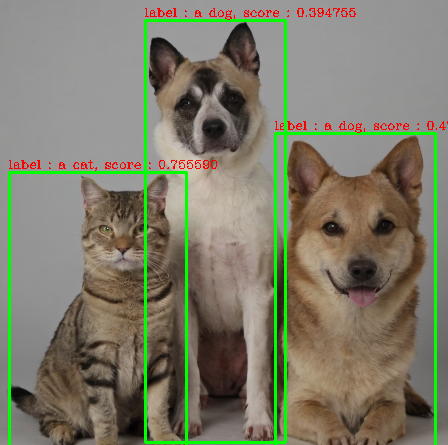
결과로 나온 results는 다음과 같은 형태입니다. 리스트 안에 딕셔너리가 있고 키 값으로 scores, labels, boxes가 있으며 scores와 boxes는 텐서 타입입니다.
[{'scores': tensor([0.7556, 0.4776, 0.3948], device='cuda:0'),
'labels': ['a cat', 'a dog', 'a dog'],
'boxes': tensor([[ 9.0255, 237.0871, 186.5573, 525.8008],
[275.1747, 198.7409, 435.3409, 526.5798],
[145.7241, 85.8307, 285.5145, 507.7950]], device='cuda:0')}]다음 함수를 이용해 results를 이미지 위에 시각화해보겠습니다. opencv를 이용해 도형을 그리는 것은 이 글에 나와있습니다.
def draw_boxes(img, results):
color = (0, 255, 0)
img_copy = img.copy()
n = len(results[0]['labels'])
boxes = results[0]['boxes'].type(torch.int64)
labels = results[0]['labels']
scores = results[0]['scores']
for i in range(n):
box = boxes[i]
x1, y1, x2, y2 = box[0].item(), box[1].item(), box[2].item(), box[3].item()
cv2.rectangle(img_copy, (x1, y1), (x2, y2), color, 2)
cv2.putText(img_copy,'label : %s, score : %f'%(labels[i], scores[i]), (x1-1, y1-4),cv2.FONT_HERSHEY_COMPLEX,0.4,(0,0,255),1)
return img_copy결과 이미지를 저장하고 주피터노트북에 출력하겠습니다.
result = draw_boxes(img_cv2,results)
cv2.imwrite('result.png',result)
temp = cv2.cvtColor(result, cv2.COLOR_BGR2RGB)
vi = Image.fromarray(temp)
display(vi)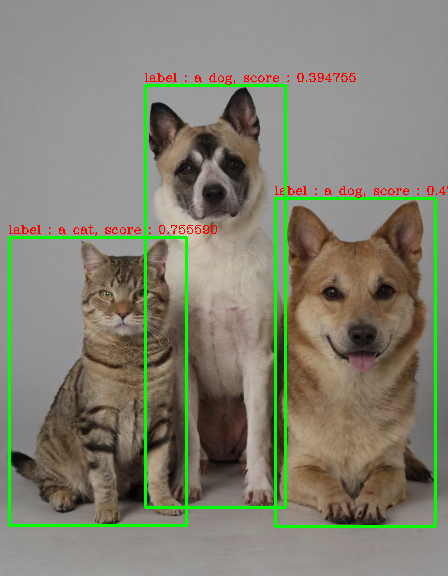
SAM에 박스전달해 세그멘테이션 하기
결과로 나온 박스를 전달하는 것 외에는 저번 글과 다를게 없습니다. 저번에는 리스트로 박스를 만들었지만 이번에는 결과로 나온 텐서형태의 박스를 입력 형태에 맞게 약간 변형해 SAM에 전달합니다.
boxes = results[0]['boxes'].unsqueeze(0).cpu()라이브러리와 모델을 불러옵니다.
from transformers import SamModel, SamProcessor
import matplotlib.pyplot as plt
import numpy as np
model = SamModel.from_pretrained("facebook/sam-vit-base").to(device)
processor = SamProcessor.from_pretrained("facebook/sam-vit-base")그리고 boxes를 모델에 전달합니다.
inputs = processor(images=img, input_boxes = boxes, return_tensors="pt").to(device)
outputs = model(**inputs)
masks = processor.image_processor.post_process_masks(
outputs.pred_masks.cpu(),
inputs["original_sizes"].cpu(),
inputs["reshaped_input_sizes"].cpu()
)이제 결과로 나온 masks를 시각화해보겠습니다. 코드에 대한 자세한 내용은 이 글에 나와 있습니다.
def mask_to_rgb(*masks):
mg = np.zeros(masks[0].shape + (4, ), dtype=np.uint8)
for mask in masks:
mg[mask == 1] = [0, 255, 0, 127]
return mg
mr0 = mask_to_rgb(masks[0][0][0],masks[0][1][0],masks[0][2][0])
mr1 = mask_to_rgb(masks[0][0][1],masks[0][1][1],masks[0][2][1])
mr2 = mask_to_rgb(masks[0][0][2],masks[0][1][2],masks[0][2][2])fig, axes = plt.subplots(1, 3)
axes[0].imshow(img)
axes[0].imshow(mr0)
axes[1].imshow(img)
axes[1].imshow(mr1)
axes[2].imshow(img)
axes[2].imshow(mr2)
for ax in axes:
ax.axis('off')
plt.tight_layout()
plt.show()