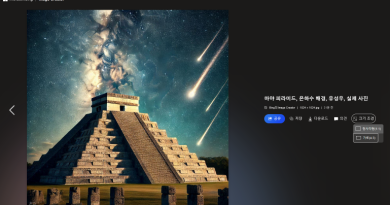
Wan2.1 FLF2V 처음 프레임, 마지막 프레임을 지정해 영상 만들기
저번(I2V, T2V)에는 Wan2.1 I2V 모델과 T2V 모델을 이용해서 동영상을 만들었는데 이후 알리바바에서 Wan2.1 FLF2V (First Last Frame To Video) 모델을 공개했습니다.
FLF2V에서는 처음 이미지와 마지막 이미지를 입력으로 넘겨 영상의 처음 프레임과 마지막 프레임을 정해줍니다. 모델은 프롬프트의 내용을 토대로 처음 이미지로 시작해 마지막 이미지로 끝나는 영상을 생성합니다.
현재는 720p에 특화된 모델만 나왔지만 더 작은 해상도로도 영상을 만들 수는 있습니다.
Wan2.1은 ComfyUI에서 사용할 수 있습니다. ComfyUI는 파이썬 기반 AI 이미지 생성 오픈소스 UI입니다. ComfyUI 실행과 ComfyUI의 사용법은 저번 글에 간단히 나와 있습니다.
이 글에서는 무료 코랩 T4 GPU에서 ComfyUI로 Wan2.1 FLF2V를 사용해보겠습니다. 무료인만큼 성능과 속도에 제한이 있고 자주 끊기기 때문에 제대로 사용하기는 힘듭니다.
성능은 떨어지게 되지만 양자화 모델을 사용해 무료 코랩의 메모리 내에서 FLF2V 모델을 사용할 수 있고 sageattention, teacache, torchcompile 등을 사용해 생성속도를 빠르게 할 수 있습니다.
아래의 주피터노트북 파일과 워크플로를 사용하겠습니다. 저번 글과 마찬가지로 주피터노트북 파일의 내용은 필요한 라이브러리 설치, 모델 다운로드, 커스텀 노드 설치, 클라우드플레어 터널링 등으로 구성되어 있습니다. 코랩이나 ComfyUI의 버전이 업데이트 되면 잘 안 될수도 있습니다.
이 글의 워크플로우는 ComfyUI Blog의 워크플로우에서 모델을 로드하는 부분과 동영상 저장 부분을 변경했습니다.
코랩에서 순서대로 셀들을 실행해 ComfyUI를 실행하고 클라우드플레어에서 제공하는 주소로 접속합니다. 그리고 ComfyUI 화면이 나오면 워크플로를 불러옵니다. 단축키는 Ctrl + O이고 워크플로 파일을 끌어서 ComfyUI 화면에 두어도 불러와집니다.
커스텀노드 설치
커스텀노드를 설치하기 위해 화면우측상단의 Manager를 클릭해 ComfyUI Manager를 열어줍니다.
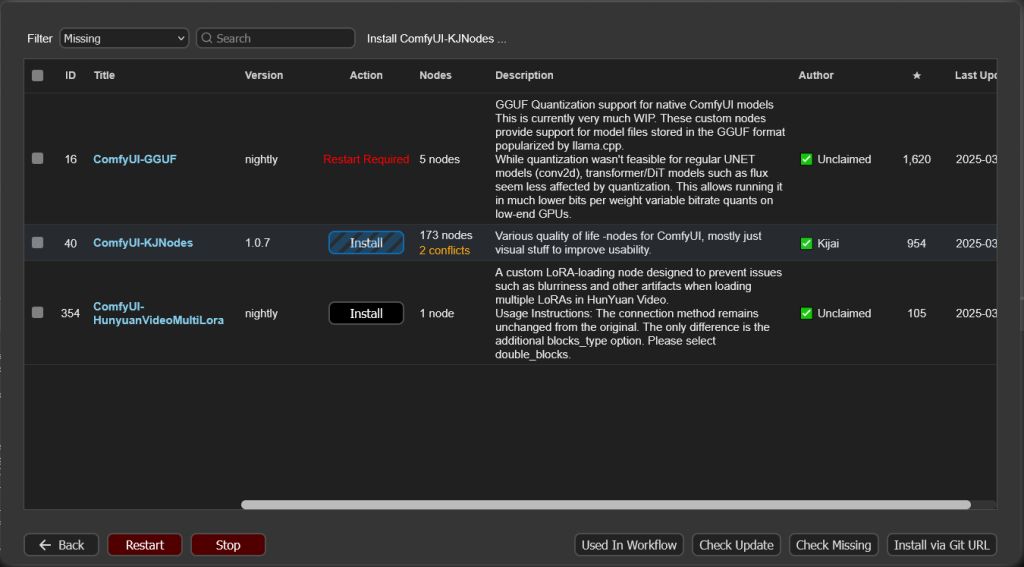
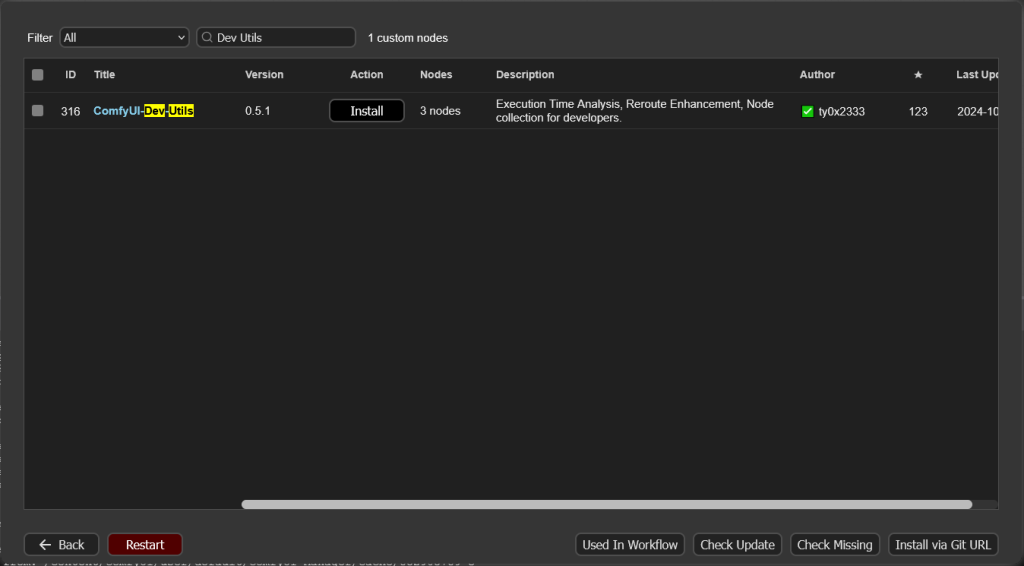
Install Missing Custom Nodes를 클릭해 커스텀노드들을 설치해줍니다. 추가로 노드의 실행시간을 보려면 Custom Nodes Manager에 들어가 Dev Utils를 검색해 설치하면 됩니다. 다 설치했으면 안내에 따라 버튼을 클릭해 재시작과 새로고침을 해줍니다.
모델 로드
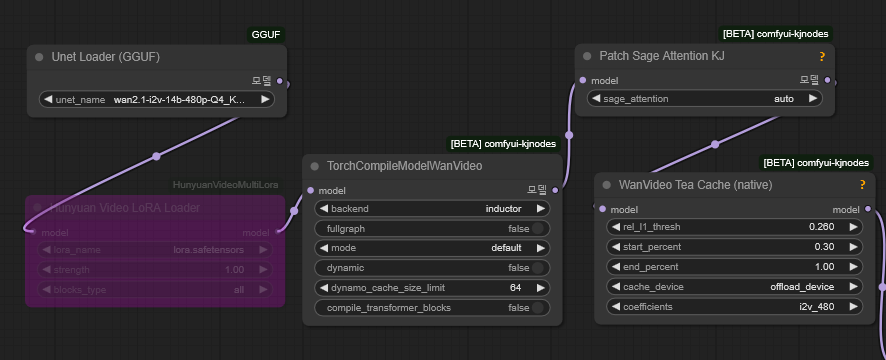
gguf 파일을 불러오고 TorchCompileModelWanVideo, Patch Sage Attention KJ, WanVideo Tea Cache (native) 등의 노드를 통해 속도를 개선합니다. 생성 속도가 빨라지는 대신 성능이 떨어질 수 있습니다. teacache의 경우 thresh값이 높을수록 생성속도가 빨라집니다. 만약 LoRA가 있다면 노드를 활성화해서 사용하면 됩니다. LoRA는 추가적인 학습에 대한 파일로 Civitai 같은 사이트에서 찾을 수 있습니다.
clip, clip_vision, vae도 불러옵니다.
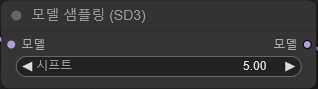
Shift, CFG, 스텝 수, 시드
Shift는 생성결과에 영향을 주는 값인데 해상도에 따라 적당한 값이 다른 것으로 보입니다. cfg의 경우 값이 높을수록 프롬프트를 잘 따르고 결과가 화려해집니다. https://replicate.com/blog/wan-21-parameter-sweep 이 링크에 shift와 cfg에 따른 비교가 나와있습니다.
샘플러의 스텝 수가 높으면 생성결과 품질이 좋지만 시간이 오래걸립니다. 그리고 스텝수에 따라서도 결과가 바뀝니다.
시드가 바뀌면 프롬프트가 같아도 결과가 달라집니다.
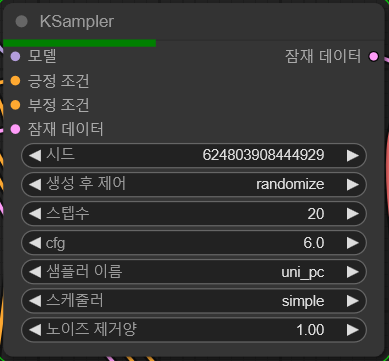
처음 이미지, 마지막 이미지 업로드
영상의 시작 프레임으로 쓰일 이미지와 마지막 프레임으로 쓰일 이미지를 업로드합니다. 이미지를 복사하고 노드를 누른 후 Ctrl+V로 복사한 이미지를 붙여넣기할 수도 있습니다.
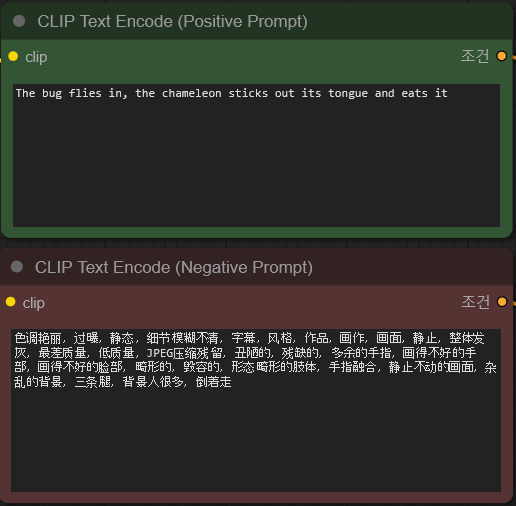
프롬프트
긍정프롬프트와 부정프롬프트를 입력합니다. 프롬프트는 자연어로 입력하고 한국어를 포함한 다양한 언어를 지원하지만 영어와 중국어가 좋다고 알려져 있습니다. ChatGPT에 이미지를 업로드하고 원하는 내용을 입력해 프롬프트를 만들어달라고 하면 잘 만들어줍니다.
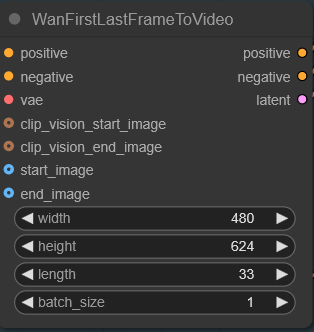
영상 너비, 높이, 길이
생성할 영상의 너비, 높이, 길이를 입력합니다. 길이는 영상의 총 프레임수와 같습니다. 영상 크기가 크고 길이가 길수록 생성하는데 시간이 많이 걸리고 메모리가 많이 필요합니다. 너비, 높이는 720p로 맞춰주는 것이 좋습니다. 하지만 무료 코랩환경에서는 720p로 맞추면 메모리가 부족하므로 720p보다 작게해줍니다. 일반적으로 480p의 경우 면적이 832*480, 720p의 경우 면적이 1280*720이 되도록 하는 것 같습니다.
무료코랩에서 480×624, 길이 33 정도에서는 잘 동작했습니다. 20스텝의 경우 모델 로딩을 포함해 9분 정도 걸렸습니다. 현재 설정된 너비, 높이, 길이로 영상을 만들 수 있는 지 테스트 해보려면 스텝수를 1로 두고 실행해서 셀이 종료 안되고 영상이 생성되는지 보면 됩니다.
결과 저장
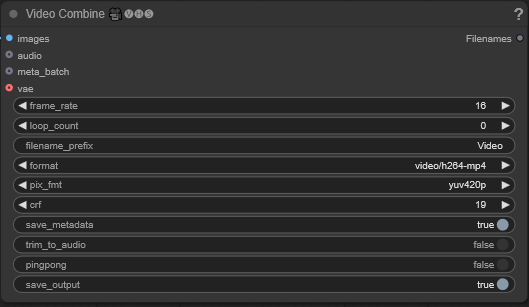
결과를 어떻게 저장할지 지정합니다. 16fps의 mp4 파일로 설정되어 있습니다. 초당 16프레임으로 길이 33의 영상을 생성했다면 2초정도가 됩니다. 파일은 ComfyUI/output 경로에 저장됩니다.
생성 결과






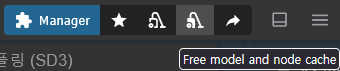
영상을 생성하고 프롬프트를 바꾸거나 새로운 이미지로 생성하면 메모리문제로 생성을 못하는 경우가 있는데 ComfyUI 오른쪽 위의 Free model and node cache를 눌러 메모리를 비우고 생성하면 됩니다. 대신 모델을 다시 불러와야하기 때문에 처음 생성할 때와 같은 시간이 걸립니다.
다른 워크플로와 Lora를 찾아서 사용해보는 것도 좋습니다.
셀이 종료된 경우에는 셀을 다시 시작하고 ComfyUI화면에서 연결되었다고 나오면 새로운 주소로 접속하지 않고 이전 화면에서 작업을 할 수 있습니다.
이 글에서는 4비트로 양자화 된 wan2.1-i2v-14b-480p-Q4_K_M.gguf을 이용했습니다. 숫자가 낮을수록 경량화 되고 숫자가 높을수록 성능이 좋습니다.